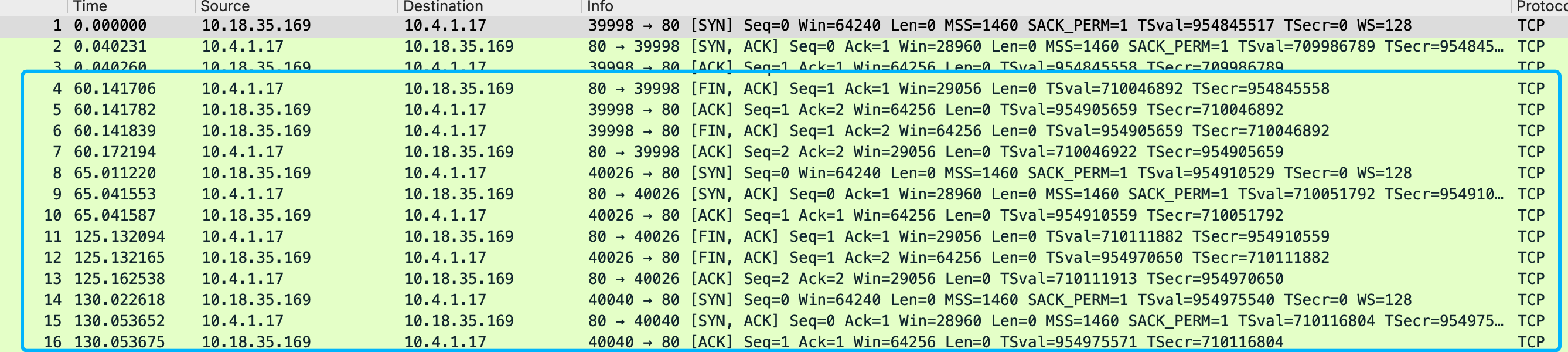
OS 为: amazon linux 2, 当开启ipv6.forwarding的时候, 发现路由就不通了
sysctl -w net.ipv6.conf.all.forwarding=1
#ping6 www.qq.co
connect: Network is unreachable
netstat -nr6 也能看到没有default route, 此时ipv6地址也无法被外部访问
如果关闭ipv6 forwarding, 那么就有默认路由, 也能ping通外部和被访问
::/0 fe80::7c:6bff:feef:ca54 UGDAe 1024 2 9 eth0
能看到路由有一个很特别的标志UGDAe, UpGatewayDynamicAllonlinkExpires
E(e): It maps to RTF_EXPIRES. It means the route has a non-infinite lifetime. In this case, the kernel probably learned the route dynamically from a RA (Router Advertisement).
这个路由其实是动态广播的, 那么这个现象就跟一个参数有关了
net.ipv6.conf.interface.accept_ra
Accept Router Advertisements; autoconfigure using them.
It also determines whether or not to transmit Router Solicitations. If and only if the functional setting is to accept Router Advertisements, Router Solicitations will be transmitted.
Possible values are: 0 Do not accept Router Advertisements. 1 Accept Router Advertisements if forwarding is disabled. 2 Overrule forwarding behaviour. Accept Router Advertisements even if forwarding is enabled.
Functional default: enabled if local forwarding is disabled. disabled if local forwarding is enabled.
Nb: per interface setting (where “interface” is the name of your network interface); “all” is a special interface: changes the settings for all interfaces
默认系统这个参数是1, 当开启forwarding的时候, 不接受路由广播, 所以这个场合, 应该修改为2, Accept Router Advertisements even if forwarding is enabled.
sysctl -w net.ipv6.conf.all.forwarding=1
sysctl -w net.ipv6.conf.eth0.accept_ra=2
备注:
UP U
GATEWAY G
REJECT !
HOST H
REINSTATE R
DYNAMIC D
MODIFIED M
DEFAULT d
ALLONLINK a
ADDRCONF c
NONEXTHOP o
EXPIRES e
CACHE c
FLOW f
POLICY p
LOCAL l
MTU u
WINDOW w
IRTT i
NOTCACHED n