spdy 协议由于安卓碎片化的存在 暂时还是需要保留一段时间的兼容性
准备升级到nginx1.14的时候发现 work process 会自动 退出, 同时系统日志有 nginx segfault的信息
修改配置,抓取coredump信息,需要做以下内容
nginx 增加
worker_rlimit_core 5000M;
working_directory /path/to/cores/;
$> ulimit -c unlimited
$> mkdir /opt/coredump/ && chown nobody.nobody /opt/coredump/ # 先建目录,还要确认nginx用户可以写此目录
$> echo “/opt/coredump/core-%e-%p-%h-%t” > /proc/sys/kernel/core_pattern
拿到coredump文件后使用gdb分析
gdb /path/to/nginx /path/to/cores/nginx.core
backtrace full
发现问题指向了
src/http/ngx_http_spdy.c:ngx_http_spdy_state_read_data 的
buf->last = ngx_cpymem(buf->last, pos, size);
简单调试发现buf->last是个0, ngx_cpymem会因为内存越界导致coredump
而分析代码 + gdb 断点调试 看到初始化r->request_body->buf的部分: ngx_http_spdy_init_request_body(r) 并未执行
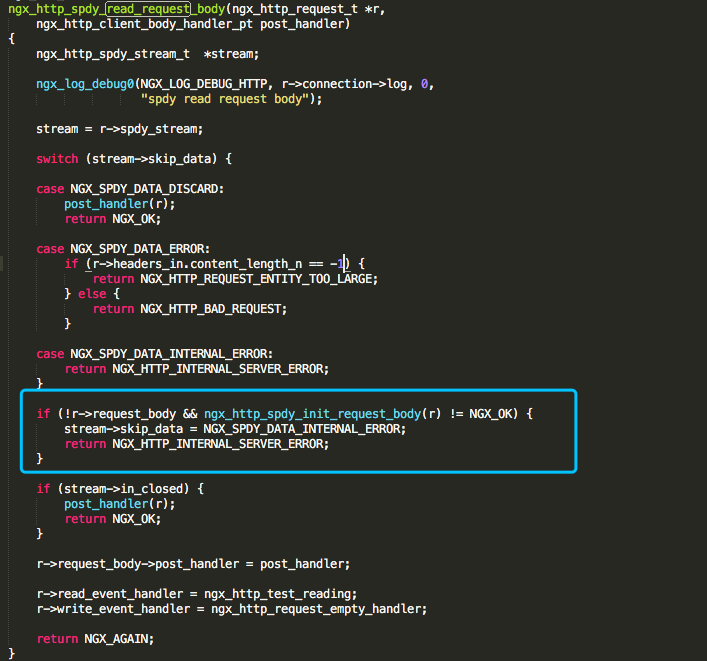
打印r->request_body 内容发现这块被初始化了,对比nginx1.12.2和1.10.3版本发现旧版本则是未做初始化
翻了下调用的部分:ngx_http_request_body: ngx_http_read_client_request_body 可以看到在nginx 1.13.12版本开始会对r->request_body 做了初始化操作,这部分直接导致了SPDY 补丁 的不兼容
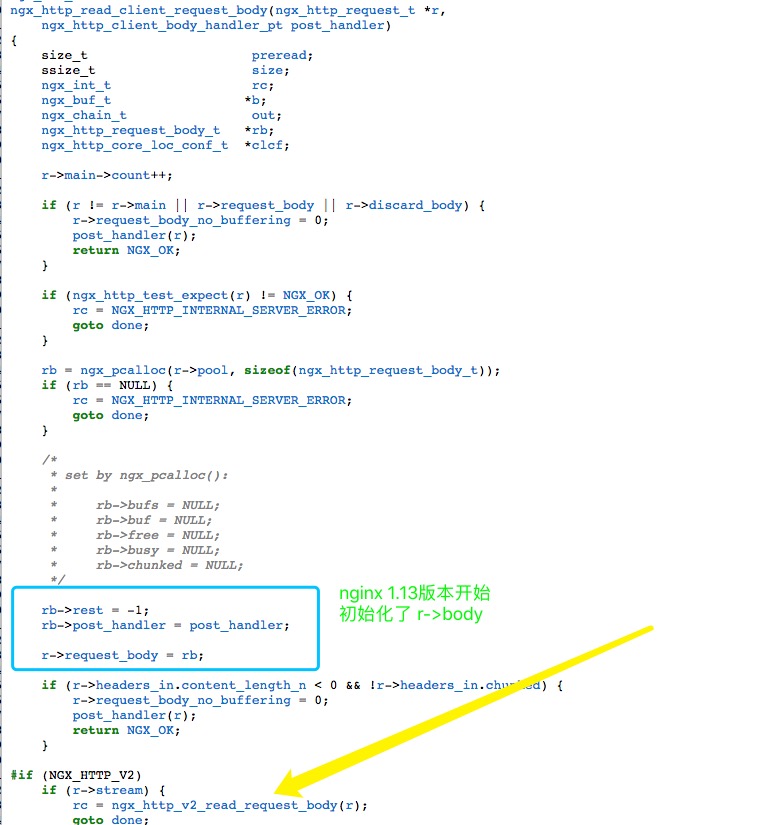
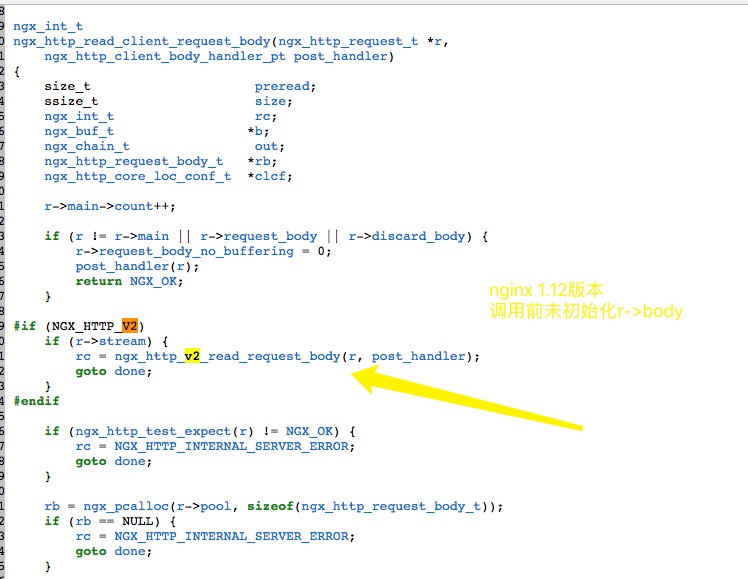
所以答案就很简单了,修改下判断条件即可
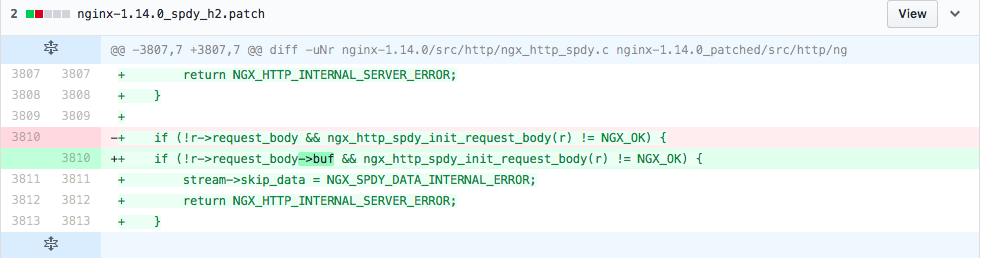
新补丁放在了:https://github.com/favortel/nginx_patch/blob/master/nginx-1.14.0_spdy_h2.patch
参考文档:
https://toontong.github.io/blog/nginx-gdb-coredump-segfault.html
https://www.nginx.com/resources/wiki/start/topics/tutorials/debugging/
http://lxr.nginx.org/source/src/http/ngx_http_request_body.c
http://lxr.nginx.org/source/src/http/ngx_http_request_body.c?v=nginx-1.12.2